| Category | Form Type | Fields | Samples | Total Fields | Field Types | Text | Long Text | Number | Date | Selection | Time | File | URL | Required |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Academic & Research | Job Application for University Positions | 4 | 50 | 200 | 2 | ✓ | ||||||||
| Grant or Research Funding Application | 6 | 50 | 300 | 5 | ✓ | ✓ | ✓ | ✓ | ||||||
| Paper Submission Form | 7 | 50 | 300 | 3 | ✓ | ✓ | ||||||||
| Student Course Registration Form | 8 | 50 | 400 | 4 | ✓ | ✓ | ✓ | |||||||
| Scholarship Application for Students | 16 | 50 | 800 | 4 | ✓ | ✓ | ✓ | ✓ | ||||||
| Professional & Business | Startup Funding Application | 18 | 50 | 900 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Real Estate Rental Application | 22 | 50 | 1,100 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Educational Workshop Registration | 17 | 50 | 850 | 4 | ✓ | ✓ | ✓ | ✓ | ||||||
| Association Membership Application | 20 | 50 | 1,000 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Arts & Creative | Art Exhibition Submission Form | 11 | 50 | 550 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
| Literary Magazine Submission Form | 11 | 50 | 550 | 5 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Conference Speaker Application Form | 14 | 50 | 700 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Technology & Software | Bug Reporting Form | 10 | 50 | 500 | 4 | ✓ | ✓ | ✓ | ✓ | |||||
| IT Support Request Form | 11 | 50 | 550 | 5 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Finance & Banking | Personal Loan Application Form | 7 | 50 | 350 | 3 | ✓ | ✓ | |||||||
| Bank Account Opening Form | 5 | 50 | 250 | 3 | ✓ | ✓ | ||||||||
| Financial Planning Consultation Form | 6 | 50 | 300 | 4 | ✓ | ✓ | ✓ | |||||||
| Healthcare & Medical | Patient Consent for Surgery | 8 | 50 | 400 | 3 | ✓ | ✓ | |||||||
| Medical Research Study Enrollment | 8 | 50 | 400 | 4 | ✓ | ✓ | ✓ | |||||||
| Health Insurance Claim Form | 10 | 50 | 400 | 5 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Legal & Compliance | NDA Submission Form | 9 | 50 | 450 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Background Check Auth. Form | 11 | 50 | 550 | 4 | ✓ | ✓ | ✓ | |||||||
| Contractor Onboarding Form | 14 | 50 | 700 | 6 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Construction & Manufacturing | Project Bid Submission Form | 13 | 50 | 650 | 5 | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Manufacturing Order Form | 13 | 50 | 650 | 5 | ✓ | ✓ | ✓ | ✓ | ✓ | |||||
| Overall | 279 | 1,250 | 13,800 | 9 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
Abstract
Online form filling is a common yet labor-intensive task involving extensive keyboard and mouse interactions. Despite the long-standing vision of automating this process with "one click," existing tools remain largely rule-based and lack generalizable, generative capabilities. Recent advances in Multimodal Large Language Models (MLLMs) have enabled promising agents for GUI-related tasks in general-purpose scenarios. However, they struggle with the unique challenges of form filling, such as flexible layouts and the difficulty of aligning textual instructions with on-screen fields. To bridge this gap, we formally define the form-filling task and propose FormFactory—an interactive benchmarking suite comprising a web-based interface, backend evaluation module, and carefully constructed dataset. Our benchmark covers diverse real-world scenarios, incorporates various field formats, and simulates high-fidelity form interactions. We conduct a comprehensive evaluation of state-of-the-art MLLMs and observe that no model surpasses 5% accuracy, underscoring the inherent difficulty of the task. These findings also reveal significant limitations in current models' visual layout reasoning and field-value alignment abilities. We hope our benchmark can serve as a stepping stone for further research into robust, practical form-filling agents.
Benchmark Construction
We developed a high-fidelity browser-based interaction platform using Python and Flask to evaluate the performance of form-filling agents. This interactive platform enables users to complete various form-filling tasks directly within a web interface, while the backend system performs real-time evaluation by automatically comparing submitted values against gold-standard field annotations. The platform comprises 20 web forms spanning eight real-world domains, including academia, finance, healthcare, and information technology. It supports a diverse range of input types, such as text fields, dropdown menus, date pickers, checkboxes, file uploads, and numerical inputs.
To simulate the complexity of real-world deployment environments, the platform incorporates a wide variety of page layouts, font styles, and color schemes. It also supports multi-page forms and modular field definitions, allowing for flexible configuration of diverse evaluation scenarios. This platform provides a realistic and compositional UI environment for large-scale, reproducible evaluation of both human annotators and multimodal models.
Demo video of the interaction platform.
Additionally, we constructed a dataset of 1,250 form-filling instances using a generative approach. Each instance consists of an input document or descriptive text paired with structured field-value annotations. The inputs include real or LLM-generated resumes, academic papers, leave requests, registration forms, and other free-form text formats. We first sample gold-standard field values from the form templates, and then prompt a large language model to generate natural language inputs that implicitly contain these values, thereby simulating realistic user behavior. For example, in job application scenarios, we generate detailed Markdown-formatted resumes, while in academic contexts, metadata is extracted from real research papers.
The final dataset comprises 13,800 field-value pairs, encompassing a wide variety of field types and input modalities. It presents significant challenges for models in terms of language understanding and layout reasoning. Detailed statistics of the dataset are provided in Table 1.
Table 1: Form field statistics across domains. "Pair Count" refers to the total number of field-value pairs. Abbreviations: Bin. Chc. = Binary Choice, Text Desp. = Text Description, Multi Chc. = Multiple Choice, Ckx. Input = Checkbox Input, Num. Input = Numeric Input. ✓ indicates the presence of a field type.
Lightweight MLLM-driven Framework
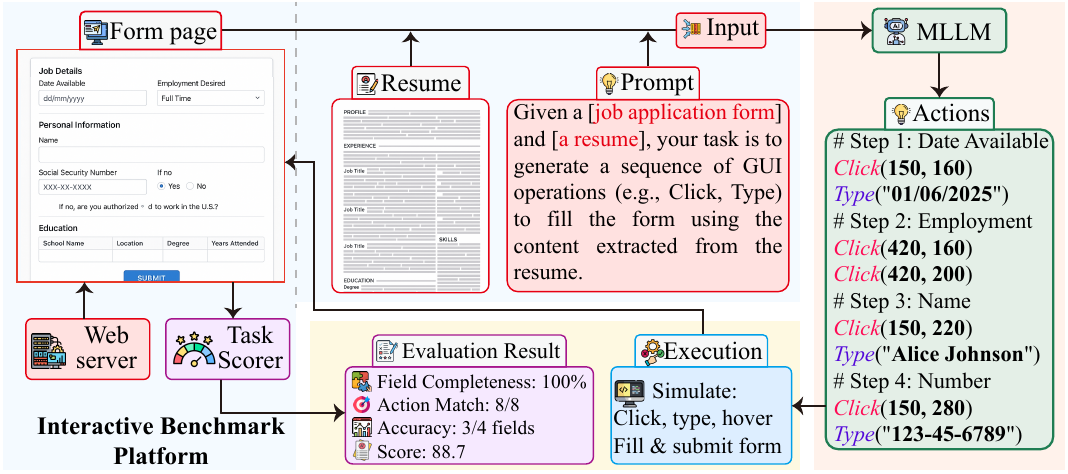
To enable automated execution and evaluation of form-filling tasks, we develop a lightweight MLLM-driven framework, shown in Figure 3. The system has three main components: a web-based form frontend, a backend scorer, and an agent execution module. Given a form and an input document (e.g., a resume), the LLM generates a sequence of GUI actions—such as Click(x, y) and Type(text)—to fill the form. These actions are executed automatically using tools like PyAutoGUI.After submission, the backend scorer compares the filled entries with ground-truth annotations and produces a detailed evaluation report, including field accuracy, action match rate, and overall task score. This framework supports scalable and fine-grained analysis of model performance in realistic form-filling tasks.
Model Performance
We evaluate several state-of-the-art MLLMs (e.g., GPT-4o, Gemini 2.5 Pro, Claude Sonnet 3.7) via their public APIs without task-specific fine-tuning, using an automated browser interface implemented with PyAutoGUI on a Windows platform. This setup enables fair assessment of the models' inherent capabilities in visual grounding, spatial reasoning, and field-value alignment. The evaluation includes both Atomic tasks (single field types) and Episodic tasks (end-to-end form filling), measuring fine-grained interaction and multi-step reasoning performance. We report two metrics: Click (UI interaction accuracy) and Value (field content accuracy), with BLEU used for generative Description fields.
| Model | String | Drop-down List | Checkbox | Radio Button | Description | Date | Check | Episodic | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Click | Value | Click | Value | Click | Value | Click | Value | Click | Value | Click | Value | Click | Value | Click | Value | |
| GPT 4o | 2.2 | 17.5 | 0.0 | 30.7 | 0.0 | 31.3 | 0.0 | 10.0 | 8.8 | 0.84 | 0.0 | 2.8 | 0.0 | 9.8 | 0.9 | 11.3 |
| Gemini 2.5 Pro | 0.9 | 98.7 | 0.0 | 99.0 | 0.0 | 76.1 | 0.0 | 52.6 | 8.1 | 0.72 | 0.0 | 99.7 | 0.0 | 79.8 | 0.4 | 70.7 |
| Claude 3.7 Sonnet | 0.0 | 95.2 | 0.0 | 66.2 | 0.0 | 72.0 | 0.0 | 97.9 | 0.0 | 0.70 | 0.0 | 99.1 | 0.0 | 55.7 | 0.0 | 58.0 |
| Qwen-VL-Max | 4.6 | 97.1 | 1.7 | 98.9 | 0.0 | 91.8 | 0.0 | 99.0 | 11.1 | 0.74 | 0.0 | 98.6 | 0.0 | 71.4 | 1.1 | 72.7 |
| Grok 3 | 0.0 | 96.2 | 0.0 | 91.2 | 0.0 | 92.4 | 0.0 | 98.1 | 5.9 | 0.71 | 0.0 | 97.9 | 0.0 | 75.5 | 0.0 | 70.7 |
| Doubao-vision-pro-32k | 0.0 | 94.2 | 0.0 | 89.7 | 0.0 | 38.6 | 0.0 | 96.9 | 0.0 | 0.51 | 0.0 | 92.1 | 0.0 | 69.9 | 0.0 | 64.7 |
Table 2: Atomic-level and episodic-level evaluation of MLLMs across different field types using Clk. and Val. metrics. GPT-4o often refuses execution despite strong capabilities, resulting in lower atomic scores. The relatively high Clk. accuracy on Description fields stems from their large input area, which tolerates less precise clicks. Episodic results measure end-to-end form completion accuracy.
Existing MLLMs still struggle to complete form-filling tasks reliably. Improving spatial reasoning and field alignment remains critical for enabling practical, GUI-driven agents in office automation scenarios.
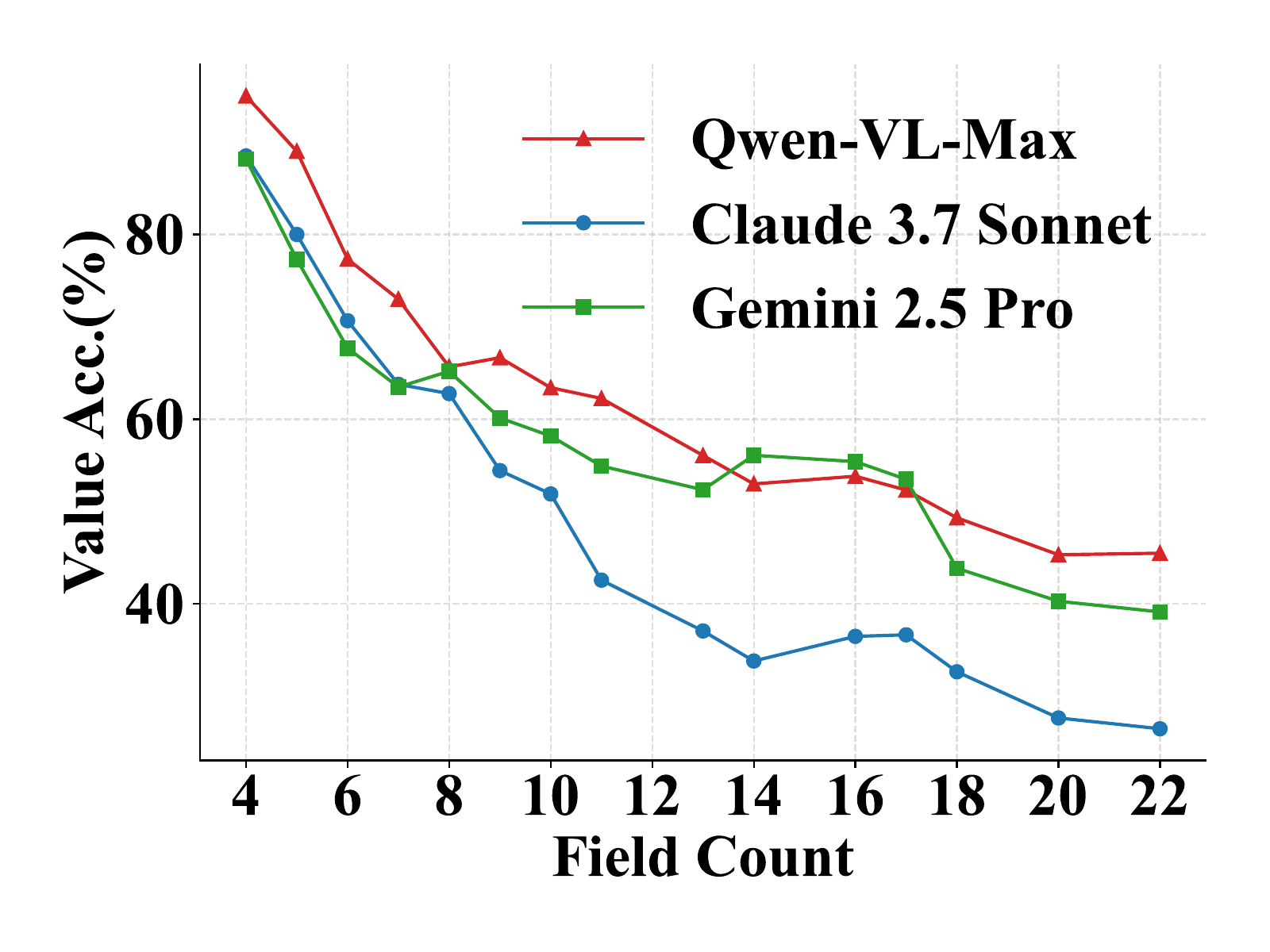
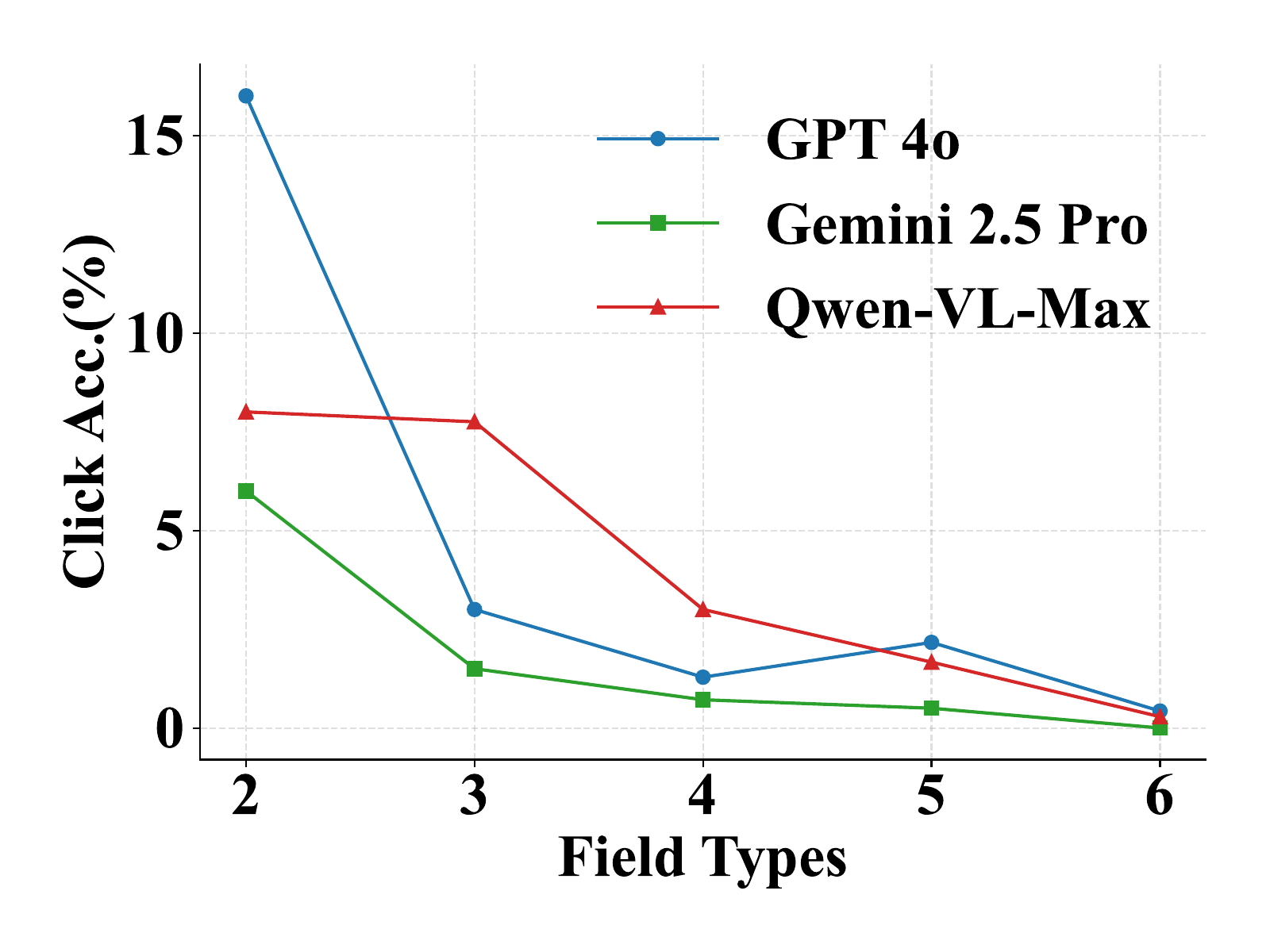
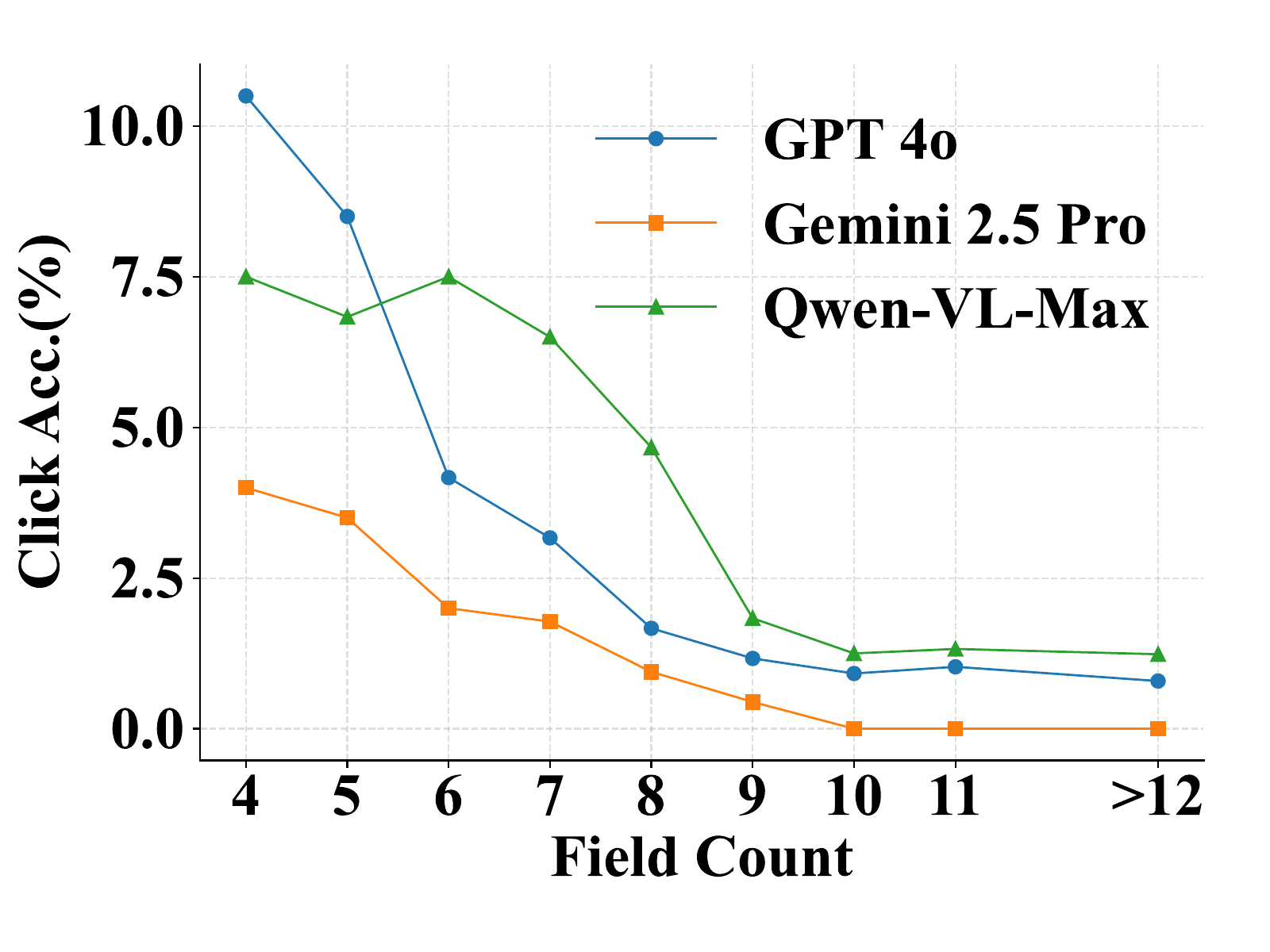
To better understand model performance beyond value prediction, we also analyze click accuracy on forms with varying numbers of fields. Click accuracy declines as the number of fields increases—a trend largely driven by higher visual complexity and denser layouts. Unlike value prediction, which applies across all field types, we report click accuracy only for String and Description fields, since model performance on other types like checkboxes and dropdowns remains consistently close to zero. Even with this filtering, click accuracy across all models remains low, highlighting the difficulty of precise pixel-level interaction and spatial grounding, even for simple text inputs.
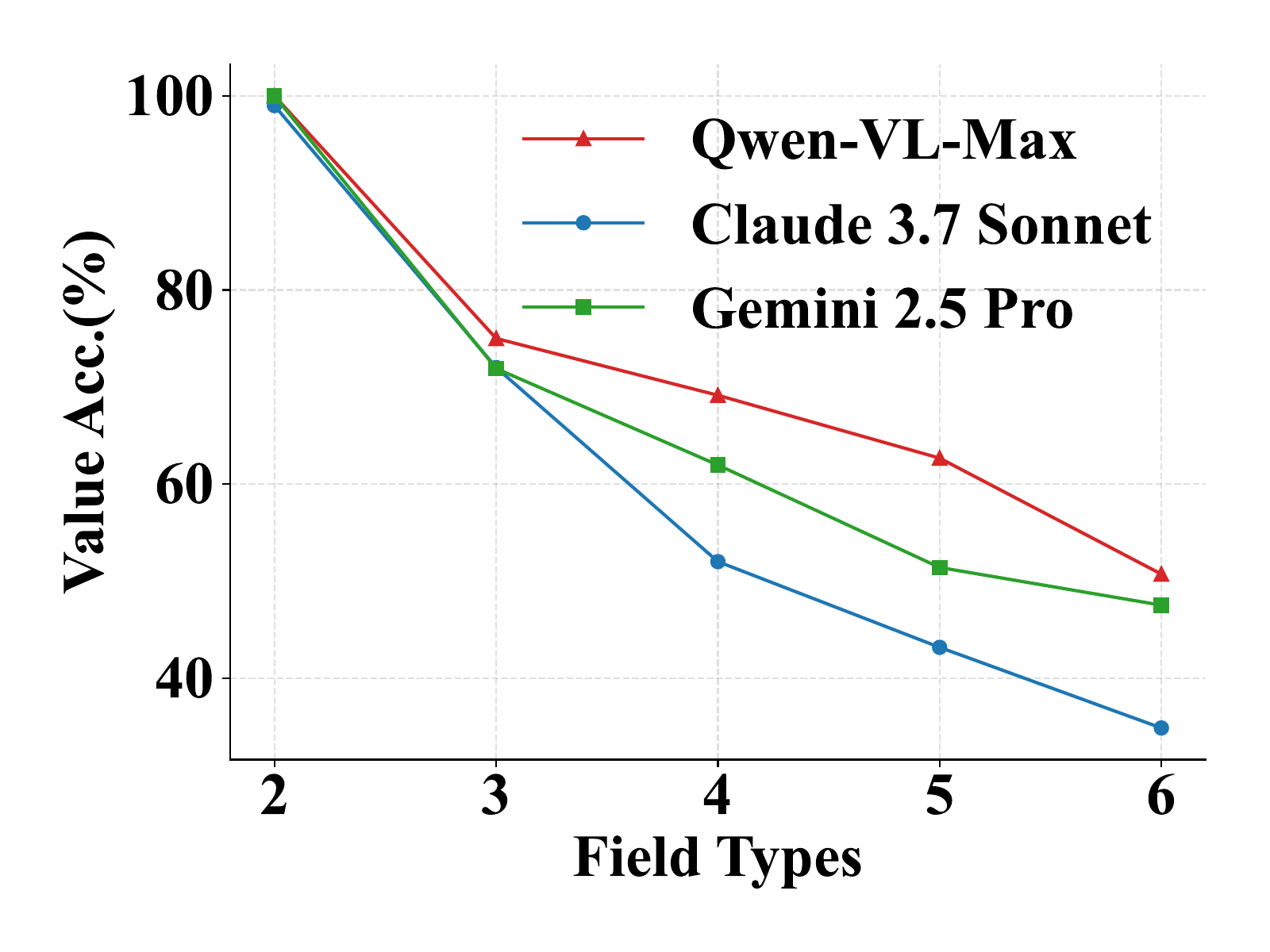
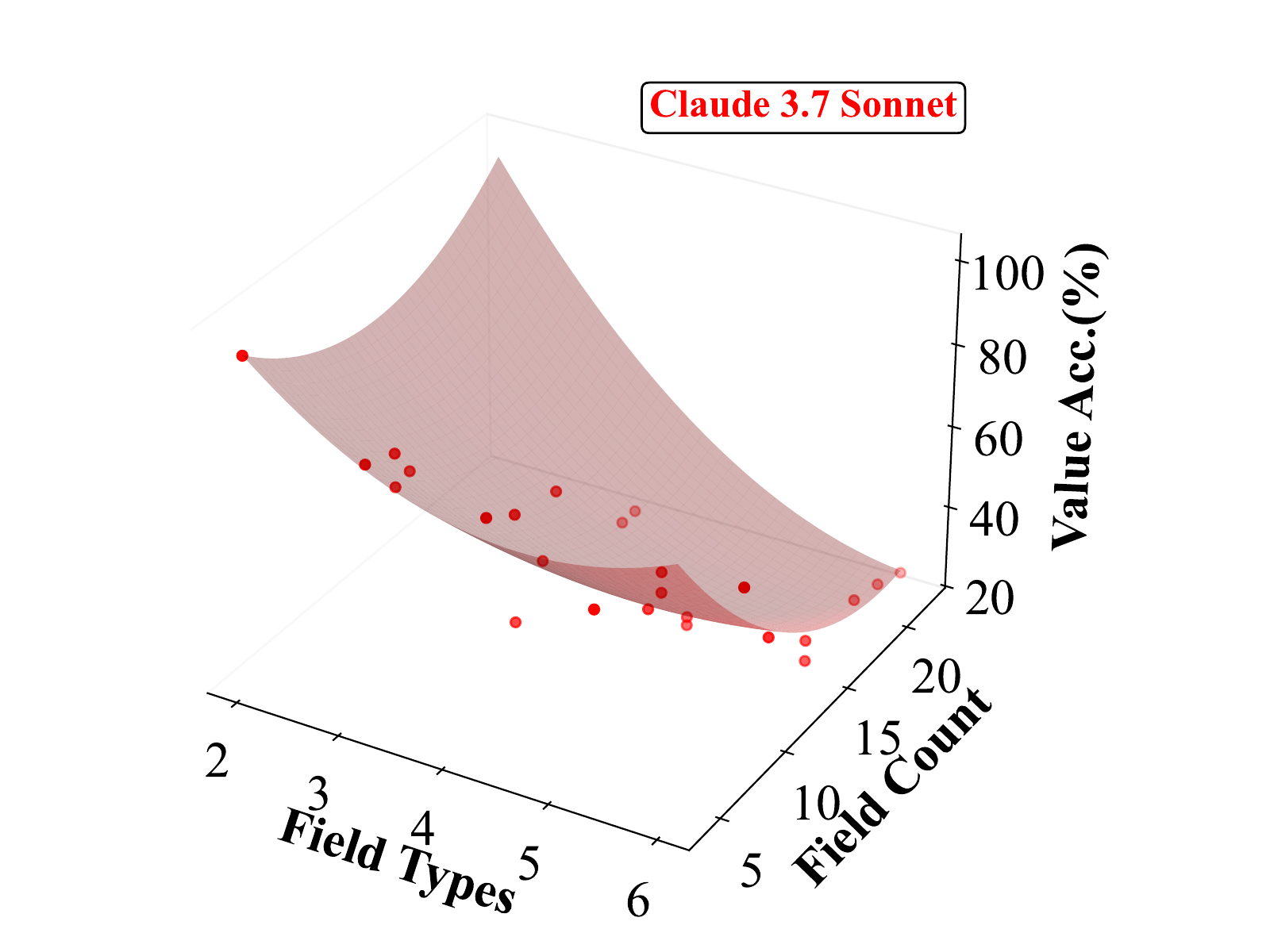
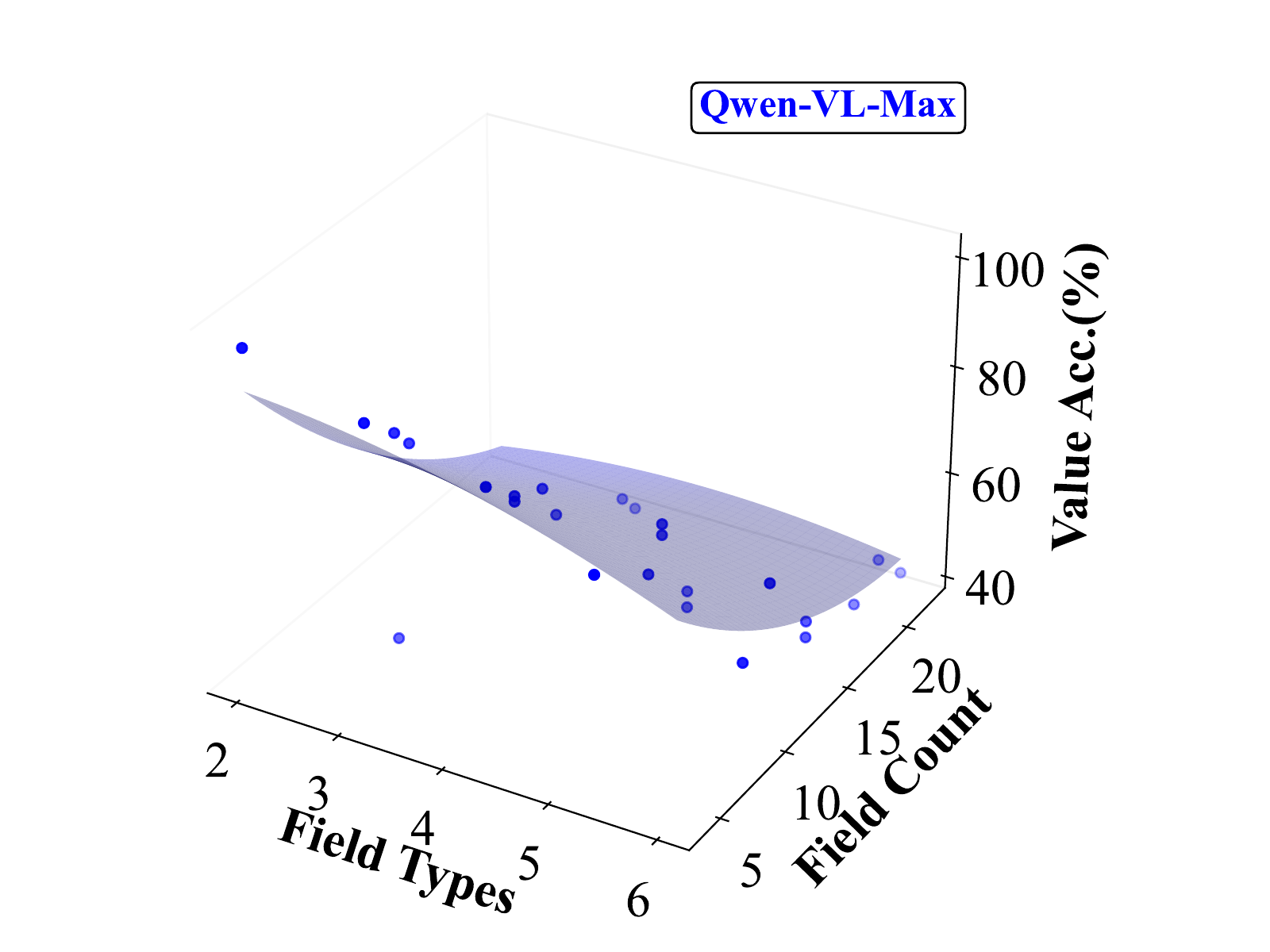
We further explore how field count and field type interact, as they often co-occur in real-world scenarios and jointly contribute to task difficulty. To capture this, we conduct a 3D analysis that examines model performance across both variables. Models perform best when both field count and type complexity are low, and worst when both are high—suggesting a strong compounding effect. This pattern supports the design of our benchmark, which intentionally includes forms with both numerous and diverse fields to stress-test spatial reasoning, alignment, and grounding capabilities in current MLLMs.